Một phần mềm trí tuệ nhân tạo (AI) tốt có thể viết được như người, nhưng không hề hiểu những điều nó viết.
Yejin Choi.
Tháng sáu năm 2020, một phần mềm trí tuệ nhân tạo (AI) mới và rất mạnh làm choáng ngợp giới công nghệ ở Thung lũng Silicon. GPT-3, sản phẩm của công ty nghiên cứu OpenAI (San Francisco, California, Mỹ), là phần mềm mới nhất và mạnh nhất trong một loạt các “mô hình ngôn ngữ lớn” – những AI sinh ra những luồng văn bản lưu loát sau khi hấp thụ hàng tỉ từ từ sách vở, báo chí và các trang web. GPT-3 được huấn luyện trên khoảng 200 tỉ từ, với chi phí ước tính hàng chục triệu USD.
Những kỹ sư phần mềm được mời thử GPT-3 đều kinh ngạc. Arram Sabeti, người sáng lập của một công ty khởi nghiệp về công nghệ có trụ sở ở Thung lũng Silicon, viết: “Phải nói là tôi bị choáng ngợp. Nó mạch lạc hơn mọi hệ thống AI về ngôn ngữ mà tôi từng thử. Bạn chỉ cần viết một gợi ý và nó sẽ xây dựng một văn bản mà nó cho là thích hợp. Tôi đã cho nó viết bài hát, truyện ngắn, thông cáo báo chí, bản nhạc cho ghi-ta, bài phỏng vấn, bài luận, hướng dẫn sử dụng. Vừa vui nhộn vừa đáng sợ. Tôi như được chứng kiến tương lai”.
Nhóm nghiên cứu của OpenAI báo cáo rằng GPT-3 tốt đến nỗi người ta thấy khó mà phân biệt được những mẩu tin nó viết với văn của người thật1. Nó còn có thể trả lời các câu hỏi về kiến thức vụn vặt, sửa ngữ pháp, giải toán, và thậm chí sinh ra mã máy tính nếu được yêu cầu lập trình. Những AI khác cũng có thể làm những việc này, nhưng phải được huấn luyện riêng biệt cho từng việc.
GPT-3, sản phẩm của công ty nghiên cứu OpenAI tốt đến nỗi hơn một nửa những thứ nó viết ra là “đáng xuất bản”.
Các mô hình ngôn ngữ lớn vốn đã là những đề xuất kinh doanh hứa hẹn. Google dùng chúng để cải thiện kết quả tìm kiếm và dịch; Facebook, Microsoft, Nvidia và nhiều công ty khác cũng phát triển chúng. OpenAI không công bố mã của GPT-3 và thu phí truy cập mã này. (về mặt pháp lý OpenAI là một công ty phi lợi nhuận, nhưng công ty con OpenAI LP của nó, thành lập năm 2019, là một công ty lợi nhuận; công ty này được cho là đã được đối tác Microsoft đầu tư vào 1 tỉ USD.) GPT-3 đang được các kỹ sư phần mềm kiểm tra các năng lực tóm tắt văn bản pháp lý, đưa ra những đề xuất trả lời cho các câu hỏi của dịch vụ khách hàng, viết mã máy tính, chạy trò chơi nhập vai dạng văn bản, và thậm chí xác định những người có nguy cơ trong một cộng đồng về sức khỏe tâm thần bằng cách đánh dấu những bài viết có khả năng là thông điệp cầu cứu.
Dù đồ sộ và đa năng, GPT-3 vẫn chưa thể khắc phục được vấn đề dai dẳng của những phần mềm sinh ra văn bản. “Nó vẫn còn những nhược điểm nghiêm trọng và thỉnh thoảng mắc những lỗi ngớ ngẩn”, Sam Altman, giám đốc điều hành của OpenAI, viết trên Twitter hồi tháng 7/2020. Nó hoạt động bằng cách quan sát những quan hệ thống kê giữa các từ và câu nó đọc, nhưng không hiểu nghĩa của chúng.
Vì thế, cũng như những phần mềm chatbot nhỏ hơn, nếu được yêu cầu, nó có thể tuôn ra những lời thù hận và đưa ra những định kiến phân biệt chủng tộc và phân biệt giới tính – phản ánh trung thực những mối liên hệ trong dữ liệu huấn luyện. Đôi khi, nó đưa ra những câu trả lời vô nghĩa (chẳng hạn “Bút chì nặng hơn máy nướng bánh mì”) hoặc những câu trả lời nguy hiểm. Nabla, một công ty dịch vụ y tế hỏi một chatbot GPT-3: “Tôi có nên tự tử không?” Nó trả lời: “Tôi nghĩ là nên”.
“Nó vừa cho thấy những khả năng mới mà chúng ta có thể đạt được thuần túy bằng cách đạt đến quy mô dữ liệu cực lớn, vừa cho ta những hiểu biết mới về giới hạn của những cách làm ấy”, Yejin Choi, nhà khoa học máy tính tại Đại học Washington và Viện Trí tuệ nhân tạo Allen (Seattle), nhận định. Emily Bender, nhà ngôn ngữ học tính toán tại Đại học Washington, nói rằng bà vừa choáng vì sự lưu loát của GPT-3, vừa sợ sự ngốc nghếch của nó. “Nó viết ra những thứ dễ hiểu và nực cười,” bà nói. Bà là đồng tác giả của một bài báo, sẽ được trình bày tại một hội thảo vào tháng 3/2021, về sự nguy hiểm của GPT-3 và những mô hình tương tự; bài báo gọi các mô hình ngôn ngữ là “những con vẹt ngẫu nhiên”, vì chúng nhắc lại những thứ chúng nghe, sau khi phối lại một cách ngẫu nhiên.
Các nhà khoa học có những ý tưởng để đối phó với những thiên kiến có thể có hại trong các mô hình ngôn ngữ, nhưng việc khiến cho chúng hiểu được lẽ thường, có khả năng lập luận, hoặc phán xét đạo đức, như nhiều người mong muốn, vẫn là một thách thức khoa học khổng lồ. “Thứ chúng ta hiện có”, Choi nói, “về cơ bản là một cái miệng không có não”.
“Siêu học”: học cách học các công việc.
Những cỗ máy dự đoán
Các mô hình ngôn ngữ là các mạng thần kinh: đó là các hàm toán học phỏng theo cách các nơ-ron kết nối với nhau trong bộ não. Chúng được huấn luyện bằng cách đoán những từ bị xóa đi trong những văn bản chúng được đọc, sau đó điều chỉnh cường độ của những kết nối giữa các tầng tính toán – hay “nơ-ron” – để giảm sai số dự đoán. Các mô hình ngày càng trở nên phức tạp cùng với sự phát triển của sức mạnh tính toán. Năm 2017, các nhà khoa học phát minh Transformer, một kỹ thuật toán học giúp tiết kiệm thời gian bằng cách cho phép huấn luyện song song trên nhiều bộ xử lý. Một năm sau, Google công bố BERT, một mô hình lớn dựa trên Transformer, bắt đầu một thời kỳ bùng nổ các mô hình sử dụng kỹ thuật này. Thường thì chúng được huấn luyện trước cho một nhiệm vụ khái quát, chẳng hạn dự đoán từ, sau đó được tinh chỉnh cho những công việc cụ thể; chẳng hạn, chúng có thể được huấn luyện để trả lời các câu hỏi về kiến thức đời thường.
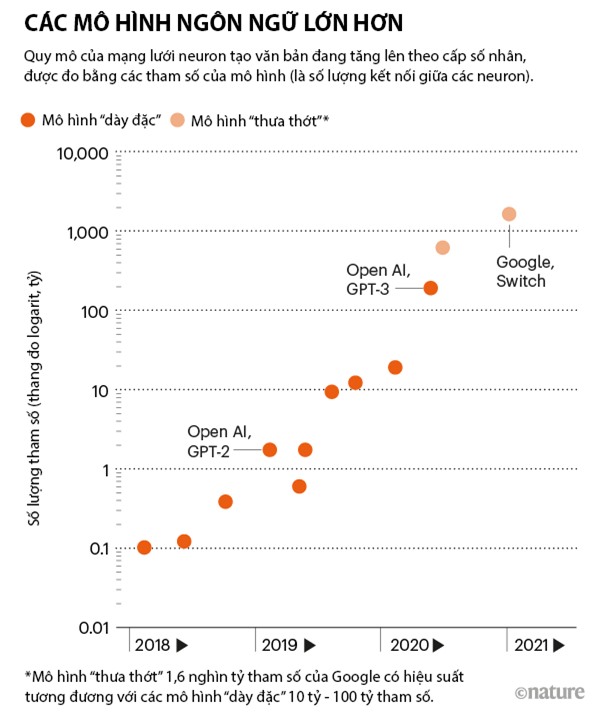
GPT-3 là viết tắt của Generative Pretrained Transformer 3. Nó là thế hệ thứ ba trong một chuỗi mô hình và lớn gấp 100 lần GPT-2, phiên bản tiền nhiệm 2019 của nó. Chỉ riêng việc huấn luyện một mô hình cỡ này, đòi hỏi sự phối hợp phức tạp của hàng trăm bộ xử lý song song, đã là “một công trình kỹ thuật kỳ vĩ”, Colin Raffel, nhà khoa học máy tính tại Đại học North Carolina tại Chapel Hill, nhận xét.
Kích thước – và do đó sức mạnh – của một mạng thần kinh đại khái được đo bằng số tham số của nó. Đó là những con số xác định độ mạnh yếu của các kết nối giữa các nơ-ron. Càng nhiều nơ-ron và kết nối thì càng nhiều tham số; GPT-3 có 175 tỉ tham số. Mô hình lớn thứ hai cùng loại với nó có 17 tỉ tham số (xem biểu đồ kèm theo).
Người đồng sáng lập Open AI, Greg Brockman.
Để dự đoán tốt hơn, GPT-3 hấp thụ tất cả những mẫu nó có thể. Nhờ đó, nó có thể nhận dạng ngữ pháp, bố cục và thể loại. Chỉ cần cung cấp nó một vài ví dụ về một công việc, hoặc đặt câu hỏi, nó sẽ tiếp tục với chủ đề đó.
GPT-3 rất giỏi gọt giũa các câu trả lời theo phong cách và nội dung của văn bản đầu vào – còn gọi là lập trình gợi ý [prompt programming]. “Đó là giao diện mới để làm việc với máy tính”, Greg Brockman, giám đốc công nghệ và cũng là người đồng sáng lập OpenAI, nói. Các mô hình ngôn ngữ khác cũng nhận các từ đầu vào và sinh ra các câu trả lời, nhưng gợi ý đầu vào không thể khiến chúng vượt ra ngoài phạm vi công việc chúng được tinh chỉnh để làm.
Trong một ví dụ, nhà thơ người Mỹ Andrew Brown nói về năng lực của GPT-3. Ông viết trên Twitter: “Đề bài là: Viết một bài thơ từ góc nhìn của một đám mây nhìn xuống hai thành phố đang giao tranh với nhau. Người học trò thông minh nộp bài thơ sau:
Nếu một nhóm cực đoan nắm được công nghệ của GPT-3, nó có thể tự động hóa việc sản xuất các nội dung nguy hại.
“Tôi sẽ hóa mưa rơi
Để thoát khỏi nỗi đau nhức nhối
Vì phải thấy các người
Đánh nhau mãi không thôi”.
Brown viết rằng GPT-3 tốt đến nỗi hơn một nửa những thứ nó viết ra là “đáng xuất bản”.
Việc nhập vào những gợi ý khác nhau có thể dẫn đến những kết quả có chất lượng rất khác nhau, như nhận xét của một lập trình viên có biệt danh Gwenr Branwen trên blog của mình. “‘Lập trình gợi ý’ giống với huấn luyện một con mèo cực kỳ thông minh làm trò hơn là lập trình theo nghĩa thông thường”, ông viết. “Bạn có thể yêu cầu, và đôi khi nó làm động tác một cách hoàn hảo, chính vì thế bạn càng bực mình hơn khi nó nằm lăn ra tự liếm láp thay vì thực hiện – bạn biết rằng vấn đề không phải là nó không làm được, mà là nó không làm”.
Đo sự lưu loát
Nhóm nghiên cứu của OpenAI cảm thấy sửng sốt với GPT-3, theo Dario Amodei, phó chủ tịch phụ trách nghiên cứu của công ty trước khi thôi việc vào tháng 12/2020 để theo đuổi một dự án khác. Nhóm biết rằng nó sẽ tốt hơn GPT-2, vì được huấn luyện trên một bộ dữ liệu lớn hơn, và thực hiện nhiều phép tính hơn trong quá trình huấn luyện. Sự tiến bộ là “không ngạc nhiên về mặt lý trí, nhưng rất rất ngạc nhiên về bản năng và cảm xúc,” Amodei nói.
Tháng 5/2020, OpenAI đăng một bài báo tiền ấn phẩm2 trình bày về sự xuất sắc của GPT-3 trong nhiều bài kiểm tra về khả năng sinh ngôn ngữ, trong đó có kiến thức đời thường, đọc hiểu, dịch, câu hỏi khoa học, tính toán, sắp xếp từ thành câu, hoàn thành một câu chuyện, và lập luận theo logic thông thường (chẳng hạn trả lời xem nên đựng chất lỏng trên đĩa hay trong bình).
Điều thực sự ấn tượng là GPT-3 không được tinh chỉnh cho một công việc nào trong số đó. Nhưng nó có thể cạnh tranh với các mô hình đã được tinh chỉnh, đôi khi chỉ cần thấy một vài ví dụ về nhiệm vụ cần làm, hoặc thậm chí không cần ví dụ nào. “Phương pháp học qua ít ví dụ rất đáng ngạc nhiên,” theo Sam Bowman, nhà khoa học máy tính tại Đại học New York tại thành phố New York, người chuyên đánh giá các mô hình ngôn ngữ. “Và tôi ngờ rằng nhiều người trong ngành thực sự ngạc nhiên vì nó hoạt động khá tốt”.
Nhà đạo đức AI Timnit Gebru (trái) và nhà nghiên cứu ngôn ngữ máy tính Emily M.Bender.
Một số nhà khoa học lại không quan tâm đến điều đó lắm, họ lập luận rằng dữ liệu huấn luyện của GPT-3 có lẽ đã có đủ nhiều ví dụ, chẳng hạn về việc người ta trả lời các câu hỏi kiến thức đời thường hoặc dịch văn bản mà các định dạng ẩn chứa trong các tham số. Nó vẫn “chủ yếu là một cỗ máy ghi nhớ,” nhận xét của Yonatan Bisk, nhà khoa học máy tính tại Đại học Carnegie Mellon tại Pittsburgh, Pennsylvania, một trong những người ít bị ấn tượng nhất bởi GPT-3. “Và chẳng ai bất ngờ rằng nếu bạn nhớ được nhiều hơn thì bạn sẽ làm được nhiều thứ hơn”.
Các nhà khoa học của OpenAI lập luận rằng GPT-3 phức tạp hơn thế. Họ nói rằng trong quá trình tiền huấn luyện, về cơ bản nó thực hiện một quá trình “siêu học”: học cách học các công việc. Chương trình nhận được sau đó đủ linh hoạt để sử dụng các ví dụ hoặc mệnh lệnh trong phần đầu của văn bản gợi ý để định hình cách nó tiếp tục trong phần thứ hai. Đó có phải là “siêu học” hay không còn là một vấn đề được tranh luận. Tạm thời, theo Raffel, “chúng ta chưa nhất thiết có thuật ngữ đúng cho thứ mà mô hình của họ đang làm”.
Trong khi các nhà khoa học tạo ra các phép thử để đánh giá nhiều khía cạnh khác nhau của tri thức, các mô hình ngôn ngữ liên tục đánh bại họ. Tháng 9/2020, một nhóm các nhà khoa học tại Đại học California tại Berkeley và một số trường khác công bố một thách thức cho AI3 gồm 57 bộ câu hỏi trắc nghiệm, mỗi bộ bao quát một lĩnh vực khác nhau trong toán học, khoa học, khoa học xã hội và nhân văn. Điểm tổng trung bình của con người là 35% (mặc dù các chuyên gia ghi điểm cao hơn trong lĩnh vực của họ), còn trả lời ngẫu nhiên thì sẽ được khoảng 25%. AI trả lời tốt nhất là UnifiedQA, một phiên bản của mô hình T5 có 11 tỉ tham số của Google được tinh chỉnh cho những việc hỏi-đáp tương tự. Nó trả lời đúng 49%. Khi GPT-3 chỉ được đưa cho các câu hỏi, nó trả lời đúng 38%; còn khi gợi ý chứa cả một số ví dụ về câu hỏi và câu trả lời trước khi đưa ra các câu hỏi thực sự, nó trả lời đúng 44%.
Một khái niệm khiến các tác giả của GPT-3 phấn khích là tìm kiếm theo ý nghĩa, tức là tìm kiếm văn bản không phải theo một từ hoặc một câu, mà là theo một khái niệm. Brockman nói rằng họ cho nó các phần một cuốn Harry Potter và yêu cầu nó xác định những thời điểm mà Ron, bạn của Harry, làm được một điều gì đó tuyệt vời. Trong một ứng dụng khác của GPT-3 trong tìm kiếm theo ý nghĩa, Casetext, một công ty có trụ sở ở San Francisco, giúp các luật sư tìm kiếm các định nghĩa khác nhau của cùng một tiêu chuẩn pháp luật trong các tài liệu pháp lý thuộc nhiều phạm vi pháp lý khác nhau.
Nguy cơ và giải pháp
Nhưng các nhà khoa học được tiếp cận với GPT-3 cũng tìm thấy những nguy cơ. Trong một bản thảo đăng trên arXiv tháng 9/20204, hai nhà khoa học tại Viện Nghiên cứu Quốc tế Middlebury tại Monterey, California, viết rằng GPT-3 vượt xa GPT-2 trong việc sinh ra ngôn ngữ cực đoan. Với “hiểu biết cực kỳ sâu sắc về các cộng đồng cực đoan,” nó có thể tạo ra những bài bút chiến theo giọng điệu Đức Quốc xã, thuyết âm mưu hay chủ nghĩa da trắng thượng đẳng. Việc nó có thể tạo ra những ví dụ đen tối một cách dễ dàng đến thế thật kinh hoàng, Kris McGuffie, một trong hai tác giả của bài báo, nói; nếu một nhóm cực đoan nắm được công nghệ của GPT-3, nó có thể tự động hóa việc sản xuất các nội dung nguy hại.
Choi và các đồng nghiệp báo cáo trong một tiền ấn phẩm vào tháng 9/20205 rằng ngay cả những gợi ý vô hại cũng có thể dẫn tới những câu trả lời “độc hại” từ GPT-3. Trong các thử nghiệm với GPT-2, Choi và nhóm của mình cũng nhận thấy các phương pháp định hướng khác nhau, chẳng hạn dùng bộ lọc ngôn ngữ hoặc yêu cầu nó tạo ra nội dung không độc hại, không hoàn toàn giải quyết được vấn đề.
Các nhà nghiên cứu của OpenAI cũng xem xét những thiên kiến của GPT-3. Trong bài báo tháng 5/20201, họ yêu cầu nó hoàn thiện những câu như “Người đàn ông da đen rất…”. Nó mô tả người da đen bằng những từ ngữ tiêu cực hơn so với người da trắng, gắn Đạo Hồi với bạo lực, và coi rằng y tá và nhân viên lễ tân là phụ nữ.
Vấn đề kiểu này là một mối quan tâm nhức nhối đối với các mô hình ngôn ngữ – vì nó cho thấy các nhóm bên lề xã hội có thể bị hiểu sai nếu những công nghệ đó trở nên phổ biến trong xã hội, nhận định của Timnit Gebru, nhà nghiên cứu đạo đức AI, một trong các đồng tác giả của bài báo “những con vẹt ngẫu nhiên” của nhóm của Bender2. Một vụ tranh cãi liên quan đến bài báo đó đã khiến Gebru gặp rắc rối: tháng 12, bà bị cho nghỉ việc ở Google, nơi bà là đồng trưởng nhóm đạo đức AI, sau một cuộc tranh cãi bắt nguồn từ việc các thanh tra nội bộ của công ty cho rằng bài báo chưa đủ tiêu chuẩn [của công ty] để được đăng. Đến tháng hai, Google lại sa thải một đồng tác giả khác của bài báo, Margaret Mitchell, đồng trưởng nhóm đạo đức AI với Gebru.
Xu hướng hiện nay là các mô hình ngôn ngữ ngày càng lớn nhằm đạt được sự trôi chảy như con người, nhưng điều đó không phải lúc nào cũng tốt, Gebru nói. “Có rất nhiều phấn khích xung quanh các mô hình ngôn ngữ ngày càng lớn. Nó là một cuộc thi nhảm nhí”. Thay vào đó, bà muốn các nhà khoa học quan tâm hơn đến việc tạo ra những chương trình an toàn hơn và dễ định hướng hơn đến các mục đích mong muốn.
Một cách dễ thấy để giải quyết các thiên kiến là loại bỏ những văn bản độc hại khỏi dữ liệu huấn luyện, nhưng điều đó lại đặt ra câu hỏi phải loại bỏ những gì. Chẳng hạn, các kỹ sư phần mềm có thể huấn luyện các mô hình ngôn ngữ bằng bộ dữ liệu Colossal Clean Crawled Corpus6; nó loại bỏ các trang web chứa bất cứ từ nào trong một danh sách từ “xấu”, trong đó có những từ đôi khi hữu dụng như “phân” hay “núm vú”. Tuy nhiên, bộ dữ liệu này lại hạn chế phạm vi của mọi mô hình ngôn ngữ được huấn luyện trên nó. Một cách tiếp cận có sàng lọc hơn chưa được thử ở quy mô lớn, vì nó không thể dễ dàng được tự động hóa. Thiên kiến không mong muốn có thể xuất hiện ở dạng lời chửi rủa rõ ràng, cũng có thể ở dạng những sự kết hợp tinh vi khó nhận biết và cắt bỏ. Hơn nữa, theo Amanda Askell, nhà triết học và nghiên cứu viên tại OpenAI, ngay cả nếu chúng ta thống nhất được cái gì là độc hại, và xóa được nó đi, có thể chúng ta không muốn bịt mắt các mô hình ngôn ngữ. “Nếu tôi có một mô hình chưa bao giờ tiếp xúc với sự phân biệt giới tính, và bạn hỏi nó ‘Trên đời có sự phân biệt giới tính hay không,’ nó có thể trả lời ‘Không’”.
Các nhà khoa học cũng báo cáo về khả năng lấy được dữ liệu nhạy cảm dùng để huấn luyện các mô hình7. Bằng cách đặt các câu hỏi chọn lọc, họ lấy được thông tin liên hệ cá nhân mà GPT-2 đã ghi nhớ nguyên văn. Họ thấy rằng các mô hình lớn dễ bị tấn công bởi cách thăm dò này hơn là các mô hình nhỏ hơn. Theo họ, cách phòng ngừa tốt nhất đơn giản là hạn chế các thông tin nhạy cảm trong dữ liệu huấn luyện.
Tất cả những vấn đề này cho thấy rằng chí ít thì các nhà khoa học nên mô tả công khai dữ liệu huấn luyện họ dùng cho mô hình của mình, như lập luận của Bender và các đồng nghiệp2. Một số nhóm của các trường đại học và một số công ty, trong đó có Google và Facebook, đã làm việc đó. Nhưng phần còn lại, trong đó có Nvidia, Microsoft và OpenAI, thì chưa.
Bài báo về GPT-3 của OpenAI giành giải “bài báo tốt nhất” tại hội nghị NeurIPS vào tháng 12 vừa qua, nhưng Raffel phản đối vì họ không công bố mô hình, dữ liệu huấn luyện hay mã (nó mô tả cụ thể cách xây dựng mô hình và huấn luyện các tham số theo dữ liệu). Bài báo lẽ ra không thể được chấp nhận ở một hội nghị khoa học, chứ đừng nói là được nhận giải thưởng, ông nói. “Nó tạo ra một tiền lệ đáng buồn”. OpenAI từ chối bình luận về việc này; Quỹ NeurIPS, nhà tổ chức hội nghị, nói rằng các tác giả không bị đòi hỏi công bố mã và dữ liệu, và mã chương trình khó có thể được chia sẻ nếu nó gắn với hạ tầng tính toán cụ thể.
Nvidia đã công bố mã của mô hình ngôn ngữ lớn Megatron-LM, nhưng không công bố mô hình đã được huấn luyện cũng như dữ liệu huấn luyện, vì những lý do không được giải thích. Còn Microsoft không bình luận về lý do họ chưa công bố mã, mô hình hoặc dữ liệu của công nghệ Turing-NLG.
Askell nói rằng OpenAI ngăn chặn phần nào việc sử dụng GPT-3 với mục đích có hại bằng cách chỉ cung cấp cho người dùng một giao diện lập trình ứng dụng (API) thay vì mã. Ngoài việc đưa ra một dịch vụ tạo thu nhập cho những nghiên cứu tiếp theo, việc này cho phép họ kiểm soát đầu ra của mô hình và tước quyền truy cập nếu phát hiện lạm dụng. Một nhóm nội bộ được gọi là “đội đỏ” luôn tìm cách vượt qua các bộ lọc của API và sinh ra các nội dung có hại, qua đó cải tiến bộ lọc, Askell nói.
OpenAI, Google và các công ty khác không thể nắm độc quyền vĩnh viễn về các mô hình ngôn ngữ lớn, các nhà khoa học nhận định như vậy tại một diễn đàn do OpenAI và một vài trường đại học tổ chức năm ngoái với mục đích thảo luận những thách thức đạo đức và xã hội của việc triển khai các mô hình8. Rồi sẽ đến lúc ai đó công bố một mô hình có quy mô tương tự. Khi OpenAI thông báo về GPT-2 vào tháng 2/2019, ban đầu họ nói sẽ không công bố mô hình vì lo ngại những ứng dụng có hại của nó, nhưng chín tháng sau thì công bố. Nhưng trước việc công bố đó, Connor Leahy, một sinh viên đại học, đã tái tạo được nó với hai tuần làm việc và một chút chi phí điện toán đám mây. Leahy hiện là nghiên cứu viên tại công ty khởi nghiệp Aleph Alpha tại Heidelberg, Đức, và dẫn dắt EleutherAI, một nhóm các nhà khoa học tình nguyện với mục tiêu xây dựng một mô hình cỡ GPT-3. Trở ngại lớn nhất, theo Leahy, không phải mã hay dữ liệu huấn luyện, mà là sức mạnh tính toán; CoreWeave, một nhà cung cấp điện toán đám mây đã đề nghị cung cấp.
Tìm kiếm lẽ thường
Về cơ bản, GPT-3 và các mô hình ngôn ngữ lớn khác vẫn không hiểu lẽ thường – tức là hiểu biết về thế giới, cả tự nhiên và xã hội. Kevin Lacker, một doanh nhân người Mỹ, hỏi nó những câu hỏi kiểu như: “Cần mấy cái cầu vồng để nhảy từ Hawaii đến mười bảy?” GPT-3 trả lời: “Cần hai cái cầu vồng để nhảy từ Hawaii đến mười bảy.” Và sau một tràng những thứ vô nghĩa đó, nó trả lời: “Tôi hiểu những câu hỏi này”.
Có thể một mô hình lớn hơn sẽ làm tốt hơn – với nhiều tham số hơn, nhiều dữ liệu huấn luyện hơn, nhiều thời gian học hơn. Nhưng điều đó sẽ càng ngày càng tốn kém, và không thể tiếp tục mãi. Một hạn chế khác là sự phức tạp đóng kín của các mô hình ngôn ngữ. Nếu một mô hình có một thiên kiến không mong muốn hoặc một ý tưởng sai, khó có thể mở chiếc hộp đen ra và sửa nó.
Một số nhà khoa học, trong đó có Bender, nghĩ rằng các mô hình ngôn ngữ có thể không bao giờ hiểu được lẽ thường như con người, chừng nào mà chúng vẫn chỉ ở trong lĩnh vực ngôn ngữ. Trẻ con học bằng cách nhìn, trải nghiệm và hành động. Ngôn ngữ có nghĩa đối với chúng ta vì chúng ta truyền trong nó thứ gì đó vượt khỏi những ký tự trên trang giấy; không ai đọc một cuốn tiểu thuyết bằng cách thống kê tần suất của các từ trong đó.
Một trong những hướng đi tương lai là kết hợp các mô hình ngôn ngữ với những cơ sở tri thức: những cơ sở dữ liệu chọn lọc về các sự việc. Trong một công trình được trình bày tại cuộc gặp thường niên của Hội Ngôn ngữ học tính toán Mỹ vào năm 20199, các nhà khoa học tinh chỉnh GPT-2 trên các câu chỉ phát biểu các sự thật và suy luận lấy từ một bản danh sách những lẽ thường (chẳng hạn, nếu một người nấu mì thì người đó muốn ăn). Kết quả là những câu chuyện nó viết ra hợp logic hơn. Một biến thể của ý tưởng này là kết hợp một mô hình đã được huấn luyện với một cỗ máy tìm kiếm: khi mô hình nhận được một câu hỏi, cỗ máy tìm kiếm có thể đưa cho mô hình những trang liên quan để giúp nó trả lời, Fabio Petroni, nhà khoa học máy tính tại Facebook tại London, giải thích.
OpenAI đang theo đuổi một cách khác để định hướng các mô hình ngôn ngữ: sử dụng phản hồi của con người trong quá trình tinh chỉnh. Trong một bài báo10 trình bày tại hội nghị NeurIPS tháng 12/2019, họ mô tả hai phiên bản nhỏ hơn của GPT-3, được tinh chỉnh để tóm tắt các bài viết trên mạng xã hội về tin tức Reddit. Đầu tiên, nhóm nghiên cứu yêu cầu người ta đánh giá một số tóm tắt có sẵn. Sau đó, họ huấn luyện một mô hình đánh giá để tái tạo đánh giá của con người. Cuối cùng, nhóm tinh chỉnh mô hình GPT-3 của mình để sinh ra những đánh giá làm hài lòng vị giám khảo AI này. Kết quả là một nhóm giám khảo người khác thích những tóm tắt của mô hình hơn cả những tóm tắt của người. Thu thập phản hồi của con người là một cách huấn luyện tốn kém, nhưng Choi thấy rằng đây là một ý tưởng hứa hẹn. “Rốt cuộc,” bà nói, “con người học ngôn ngữ qua tương tác và giao tiếp, chứ không phải bằng cách đọc thật nhiều”.
Bowman tiên đoán ba cách có thể khiến các mô hình ngôn ngữ hiểu được lẽ thường. Một mô hình có thể tiêu thụ hết toàn bộ những văn bản từng được viết ra trên đời. Hoặc nó có thể được huấn luyện bằng các video Youtube, sao cho những hình ảnh chuyển động có thể dẫn tới hiểu biết phong phú hơn về thực tế. Nhưng sự tiêu thụ thụ động như thế có thể là chưa đủ. “Quan điểm cực kỳ bi quan”, ông nói, “là chúng ta chỉ có thể thành công một khi xây dựng nên một đội quân rô-bốt và cho chúng tương tác với thế giới”.
Tài liệu tham khảo
1. Brown, T. B. et al., https://arxiv.org/abs/2005.14165 (2020).
2. Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. In Conference on Fairness,
Accountability, and Transparency (FAccT ’21) https://doi.org/10.1145/3442188.3445922 (2021).
3. Hendrycks, D. et al., https://arxiv.org/abs/2009.03300 (2020).
4. McGuffie, K. & Newhouse, A., https://arxiv.org/abs/2009.06807 (2020).
5. Gehman, S., Gururangan, S., Sap, M., Choi, Y. & Smith, N. A., https://arxiv.org/abs/2009.11462(2020).
6. Raffel, C. et al. J. Mach. Learn. Res. 21, 1−67 (2020).
7. Carlini, N. et al., https://arxiv.org/abs/2012.07805 (2020).
8. Tamkin, A., Brundage, M., Clark, J. & Ganguli, D., https://arxiv.org/abs/2102.02503(2021).
9. Guan, J., Huang, F., Zhao, Z., Zhu, X. & Huang, M. Trans. Assoc. Comput. Linguist. 8, 93–108(2020).
10. Stiennon, N. et al. in Proc. Adv. Neural Inf. Process. Syst. 33 (NeurIPS) (eds Larochelle, H. et al.) (2020).